
Таблица 1: Табличное представление количества аудиофайлов на класс перед генерацией набора данных и процент повторений на 1000000 значений набора данных
Авторы: Ahmed Hamdy, Pratap Kiran Vedula, Muni Venkata Jasantha Konduru
Автор перевода:В. Г. Шапалин
Источник:https://cs230.stanford.edu/projects_fall_2019/reports/26261998.pdf
Разделение и извлечение звука с помощью глубокой нейросети
Ahmed Hamdy |
Pratap Kiran Vedula |
Muni Venkata Jasantha Konduru |
Зачастую, интересующий нас определённый звук перекрывается множеством других волн из различных источников, и если они имеют сопоставимую, если не выше, амплитуду, то снижается способность эффективно воспринимать прослушиваемый звук. Разделение и извлечение звука позволит нам сосредоточиться на специфичных, интересующих нас звуках. Целью работы является возможность разделить и извлечь «смешанный» аудиофайл, используя глубокое обучение. Реализованная модель свёрточного автокодировщика содержит кодирующий уровень с двумя свёрточными слоями, за которыми идёт один полносвязный слой, за которым следует декодирующий уровень, содержащий массив полносвязных слоёв и два деконволюционных слоя на класс.
Разделение и извлечение звука требует обученной системы, когда представленный неизвестный звук может быть правильно идентифицирован и извлечён. Мы предлагаем решение так называемой «проблемы коктейльной вечеринки». Реализованная модель «изучит» и применит различные фильтры ко входному сигналу для того чтобы получить набор отдельных источников звука из смешанного входного значения. Несколько сценариев-примеров, которые мы попытались включить, это беспилотные автомобили, распознающие сирену, изоляция голоса ведущего из звуков среди шумной толпы, или распознавание детского плача в шумном окружении. Сложным аспектом данного проекта было обучение нейросети с большим набором данных. Мы решили предобработать полный набор данных сразу и столкнулись с ограничениями памяти, тогда мы решили делать обработку частями. Входные данные для нашего алгоритма – это смешанный аудиофайл, состоящий из разных звуков, перекрывающих друг друга. Выход классифицируется на пять отдельных аудиофайлов. Мы использовали фреймворк PyTorch для работы и использовали оконное преобразование Фурье для извлечения признаков и ограничения по минимальному и максимальному значению для нормализации данных.
Наша модель пытается решить проблему разделения источников звука, основывая свой
CS230: Deep Learning, Winter 2018, Stanford University, CA. (LateX template borrowed from NIPS 2017.)
подход на похожих работах таких людей, как Чандна, Притиш и других[7]. Их модели разделения звуков, несмотря на то, что они были созданы с нуля из-за недостатка инструментов, которые решали бы проблему коктейльной вечеринки, и в тоже время были просты в понимании и редактировании написанного кода. Исследования, сделанные Стефаном Улихом, Антуаном Лиуткусом и Юки Митсуфуджи [10] предложили реализовать Open-Unmix для разделения музыки и задач для декомпозиции музыки на её базовые компоненты, такие как вокал, басс и барабаны. Эта модель была принята как образцовая [11] для сравнения реализаций.
Мы делали исследования с различными опциями для генерации данных, что позволит нам создать входные и выходные аудиофайлы для разделения и извлечения звука. Основные категории используемых аудиофрагментов это музыка, человек, человеческая речь, звуки природы, городские звуки и шумы. Все звуки доступны из базы данных Making Sense of Sounds Challenge (MSoS) 2018 [1], the Spoken Wikipedia Corpora (SWC) [2]. Сирена, детский плач и собачий лай были взяты из Kaggle [5] и GitHub [2][3].
Аудиофайлы для обучения являлись набором составных звуков из 4 различных источников соответствующих общим разделам (1) Деский Плач, (2) Сирена, (3) Собачий лай, (4) Человеческая Речь, взятые из упомянутых выше категорий и смешанные вместе для создания входного файла. Далее мы наложили 2 случайно выбранных дополнительных аудиофайла из класса (5) Другое на входной аудиофайл. Все несмешанные аудиофайлы соответственно классифицируются как выходные. Как часть генерации набора данных, каждый аудиофайл делится на 5-секундные куски, высота тона смещается на 2 или 4 шага, случайно растягиваются в 1.2 раза, и громкость смещается на случайное значение между значениями -5 и +5. Благодаря этим операциям, мы убедимся, что обучение происходит правильно, с надёжным набором данных. Сгенерированные аудиофайлы являются 5-секундными отрывками, закодироваными с помощью ИКМ и формате WAV, с одноканальным звуком и частотой дискретизации 44100 Гц. Таблица 1 ниже показывет изначальные раздельные классы аудиофайлов, использованные для генерации 100000 наборов данных, и процентное количество копий в сгенерированных наборах данных. Заметим, что наборы сгенерированных данных разнообразны, с минимальным количеством копий и перекрываний.
Таблица 1: Табличное представление количества аудиофайлов на класс перед генерацией набора данных и процент повторений на 1000000 значений набора данных
Предобработка заключается в конвертации входных аудиофайлов к 22050 Гц, уменьшении продолжительности аудиофайла до 3 секунд, нормализации параметров с помощью функции Min-Max, и извлечение оконного преобразования Фурье из входного и выходного файлов. При трансформации аудио, размер окна выбирается в 23 милисекунды, а длина смещения – четверть имеющегося окна. Рисунки 1 и 2 показывают образец спектрограммы оконного преобразования Фурье для входных и выходных файлов. Мы использовали 100000 файлов как часть нашего набора данных. 92 процента данных мы использовали для обучающей выборки, а остальные 8 – для тестовой выборки.

Рисунок 1: спектрограмма оконного преобразования Фурье для входного файла

Рисунок 2: спектрограмма оконного преобразования Фурье для набора выходных файлов, представляющих детский плач, сирену, собачий лай, человеческую речь и другое соответственно
Мы реализовали этап кодирования, состоящий из двух свёрточных слоёв, за которым идёт полносвязный слой, а декодирующий этап обрабатывается параллельно для каждого из наших пяти классов, и состоит из одного полносвязного слоя, за которым следует два обратных свёрточных слоя. Вся операция представлена на рисунке 3.
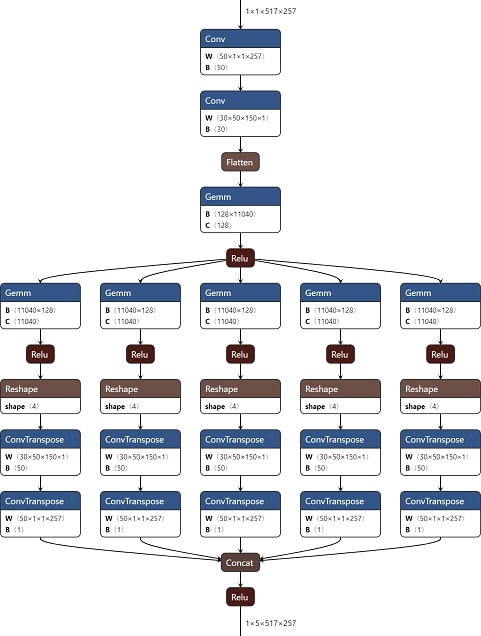
Рисунок 3: Графическое представление модели архитектуры
Слои на кодирующем этапе имеют следующие функции: (1) вертикальный свёрточный слой, необходимый для получения частотной характеристики, (2) горизонтальный свёрточный слой, необходимый для получения характеристики, зависящей от времени, таким образом получая частотно-временную характеристику, и (3) полносвязный слой с функцией ReLU для активации, который передаёт свой вывод на слои в декодирующем уровне. Слои на каждом из декодирующих этапов являются: (1) полносвязным слоем, который имеет те же размеры, что и кодирующий горизонтальный свёрточный слой для минимальной потери информации, с функцией активации ReLU, также, как и (2) горизотальный (3) и вертикальный слой обратной свёртки, которые имеют размер, противоположный горизонтальному и вертикальному слоям свёртки на уровне кодирования. Вывод каждого из пяти декодирующих уровней затем объединяется для активации с помощью ReLU, прежде чем использоваться для расчёта потерь и работы обратного распространения ошибки.
Модель представлена смешанным входным источником и пятью выходными источниками, где всё проходит через извлечение признаков и нормализация, а затем пробует обучаться на амплитуде входного оконного преобразования Фурье, игнорируя фазу. Было обнаружено, что вместо обучения на значении и амплитуды, и фазы входного Фурье-преобразования, обучение только на амплитуде без фазовой составляющей на входе каждого из пяти выходов имеет незначительную разницу в качестве сигнала с точки зрения отношения источника к помехам между (а) выходным сигналом с соответствующей амплитудой и фазой и (б) выходным сигналом с соотетствующей амплитудой, но входной фазой. К тому же данный способ уменьшает количество параметров для обучения в 2 раза по сравнению с обучением на амплитуде и фазе входного преобразованного сигнала. Затем модель обучается на наборе из пяти различных фильтров, которые применяются на входа для получения пяти выходных значению, представляющих раздельные источники, которые расчитываются следующим образом:
Когда фильтры применяются на вход для получения пяти выходных значений, расчитываются потери на каждый класс, как среднеквадратичная ошибка между расчитанным и имеющимся выходным значением. Потери для каждого случая затем суммируются вместе для оптимизации с помощью алгоритма оптимизации ADAM [8]. Метод скоростного адаптивного обучения (ADADELTA) , предложенный Зейлером, Метью Д. [12] также был протестирован для адаптации скорости обучения динамически по временному параметру.
На протяжении тестирования итеративного процесса для нахождения оптимальных переменных для модели, мы пришли к набору параметров, которые мы оценили в сочетании друг с другом для обучения модели. Подмножество этих параметров обобщены в таблице 2, где они внесли вклад в (1) размер скрытых элементов (FC Features, Horizontal and Vertical Conv. Filter Sizes), (2) размер входных данных(STFT Size, STFT Hop Length, Sample Rate), (3) отпимизация потерь(ADAM and ADADELTA as well as their respective parameters), (4) итерации обучения(Epochs), (5) методы нормализации (MIN MAX and CMVN), и (5)размер набора данных.
|
Parameters |
|
Options |
|
|
Optimizer |
ADAM |
ADADELTA |
|
|
ADAM Learning Rate |
0.01 |
0.005 |
0.001 |
|
ADADELTA rho |
0.98 |
0.95 |
0.9 |
|
STFT Size |
1024 |
512 |
|
|
STFT Hop Length |
256 |
128 |
|
|
Horizontal Conv. Filter Size |
(1, 513) |
(1, 257) |
|
|
Vertical Conv. Filter Size |
(15, 1) |
(350, 1) |
(150, 1) |
|
FC Features |
128 |
376 |
|
|
Normalization |
MIN MAX |
CMVN |
|
Таблица 2: Табличное представление подмножества различных обработанных параметров
Некоторые комбинации данных параметров были исследованы, с которыми подмножество давало желаемые результаты. Оптимальная ошибка Байеса в этом случае это та, где средние потери равны 0, и с дальнейшей оценкой мы определили «человеческий» уровень с средними потерями около 35 для отдельного выхода с приемлемой интерференцией и качеством затухания сигнала. Базовая модель, с которой мы начали была построена с нулевым заполнением и свёрточные слои также оптимизированы напрямую на потери на выходе. Используя эту модель, средняя ошибка на выходе при обучении составляла 250000, что существенно и несёт за собой большие проблемы смещения. Цель нулевого заполнения со свёрточными слоями чтобы декодирующий уровень сохранял размер входного волнового сигнала, чтобы воссоздать его в отдельном выходном сигнале. Сохраняя ту же цель, мы поняли, что использование слоев обратной свёртки более предпочтительный метод для использования его в попытке развернуть операцию свёртки на кодирующем уровне. Это уменьшает ошибку обучения до 40000, что является вполне желаемым уменьшением ошибки, хоть и далёким от идеала. Затем мы попытались оптимизировать ошибку на выходном фильтре, как было предложено Чадной, Притишем и др. [7] и описано в разделе выше, и мы можем наблюдать ошибку обучения в 1700. Затем мы приняли к объединенной выходной модели и использовали ADAM [8] как и к нашему оптимизатору ошибок, и увидели, что ошибка уменьшилась до 240, в то время как на тестовой выборке ошибка составляла 272. Разобравшись с этим, мы можем обратиться к нашей проблеме смещения, хотя сейчас наблюдается проблема дисперсии. Сосредоточившись на уменьшении смещения для времени, мы попытались оптимизировать обучение, используя CMVN вместо функции MIN-MAX для нормализации, что привело к средней ошибке в 219 и 204 на тестовой выборке, что ещё уменьшило смещение, хоть теперь мы понимаем, что наша тестовая выборка может быть обработана легче из-за меньшей ошибки, чем у тренировочной выборки. Рассматривая распределение наборов данных по классам, мы поняли, что примерно 5% сигналов смешаны с каждым из классов (кроме «других»), что означает, что они заполнены полезными данными, пока остальные 95% - это тишина. Из этого можно сделать вывод, что наши тестовые наборы данных легко предсказать, особенно если большой процент из них – это тишина, учитывая, что мы тренировались на большом количестве «тихих» сигналов. Опосредованно, эта проблема было возможно решить, убедившись, что отношение сигналов с информацией к «тихим» сигналам 70/30 (за исключением категории «Другие»).
Исходя из этого, после нескольких тестов, финальная модель, на которой мы остановились, была эквивалентна модели, подробно разобранной в предыдущем разделе, которая имела средний показатель ошибки в 60 для обучающей выборки и 129 для тестовой, имеем ввиду, что модель переобучилась, так как мы видим большую дисперсию, и для решения этой проблемы, необходимо увеличить набор данных для обучения. В таблице 3 представленны подсчитанные подмножества оцениваемых тестов.
Для измерения предсказательной силы модели, мы используем метрику mir_eval, предложенную Раффелом, Колином, и др. [9] т.к., библиотека предоставляет нам возможность расчёта предполагаемого источника для случая
|
Тестирование |
Средняя ошибка в обуч. выб. |
Средняя ошибка в тест. выб. |
|
A Заполнение нулями + Свёрточные слои и слои обратной свёртки |
40000 |
- |
|
B Обучение фильтров в выход модели |
1700 |
- |
|
C Использование ADADELTA для оптимизации ошибок и Добавление ReLU к выходу модели |
240 |
272 |
|
D Изменение MIN-MAX на CMVN нормализацию |
219 |
204 |
|
E Увеличение размера функций FC до 376 |
237 |
225 |
|
F Изменить CMVN на MIN-MAX с ADADELTA с ADAM при LR 0.001 а также уменьшить функции FC до 128 |
66 |
129 |
Таблица 3: Табличное представление различных обработанных параметров
когда необходимо выполнить задачи разделения на источнки, основанные на отношениях сигнала к искажениям(SDR), отношениях источника к помехам(SIR), отношениях источника к артефактам(SAR). Запустив несколько из этих моделей, протестированных ранее через соответствующие инструменты разработчика, мы можем наблюдать расчёт метрик для класса, как показанно на рисунке 4.
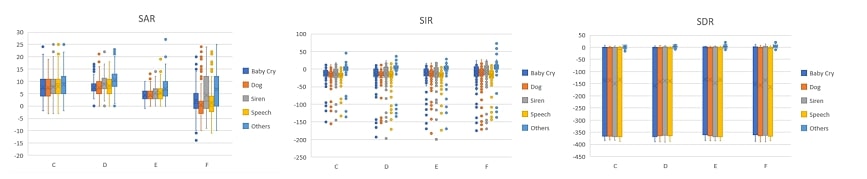
Рисунок 4: Расчёты метрик для каждого класса в тестируемой модели
Мы можем заметить, что средняя ошибка в тестовых данных, определенная раньше, коррелирует с представленными рассчитанными метриками, что мы можем видеть на каждой SAR, SIR и SDR для модели D, что является лучшей по сравнению с моделями C и E. Тем не менее, мы можем понять, что SDR для всех моделей, представленных выше имеет среднее значение около -150, что влечёт за собой то, что правильный результат не особо соответствует полученному на выходе. SIR представляет лучшие результаты, хотя средний результат колеблется в районе -10, из чего можно сделать вывод, что предполагаемый выход разделяет некоторую часть сигнала с другими выходами, что мы будем слышать как небольшие помехи среди классов. Это, тем не менее, не является большой проблемой, поскольку SAR предоставляет нам результат со средней ошибкой в 8, что значит, отделённый выходной сигнал не имеет искажений и обладает минимальным количеством помех. Сравнить наши результаты с опубликованными работами было проблематично ввиду малого количетва реализаций разделения звука на составляющие, рассматривающие общие звуки, а не концентрирующиеся на обработке музыки. Тем не менее, так как конечная цель одиннакова, а у нас существует класс человеческой речи, что можно принять за вокал, мы составили таблицу 4 для сравнения результатов нашей реализации и реализации на Open-Unmix [10], которая была заявлена как передовая модель от Sinal Separation Evaluation Campaign 2018 [11]. Мы можем видеть, что несмотря на то, что наша SAR лучше по качеству, SIR и SDR извлекают сигнал намного хуже по сравнениею с Open-Unmix.
Модель SDR SIR SAR
Open-Unmix 6.32 13.33 6.52
Модель СНС -139 -18.7 8
Таблица 4: Сравнение передовой модели Open-Unmix и нашей реализации
Главной целью этого проекта была попытка классифицировать и извлечь звуки из смешнанного входного аудиофайла с помощью оконного Фурье-преобразования для дальнейшей нормализации с помощью MIN-MAX. Пока мы смогли достигнуть ождаемых результатов в пяти категориях, для дальнейшего понимания, необходимо обучить модель на большем количестве данных. Будущие работы будут включать: (1) получение мел-спектрограммы, показывающей преобразование звуков по мел шкале, (2) обучение на большем наборе данных для исправления проблемы отклонения, (3) исследование использования сетей долгой краткосрочной памяти(LSTM) для обучения сети на коротких сигналах, в реальном времени, и (4) учёт условия дискриминационных потерь в каждом классе для дальнейшего их уменьшения в SDR и SIR.
Проходя набор различных задач, усилия и вклад в проект распределились поровну между всеми членами этой группы. Таблица 5 показывает подробно задачи, выполняемые каждым участником группы.
GitHub Репозиторий: https://github.com/ahpvjk/audio-classification-and-isolation
[1] Harris, Lara; Bones, Oliver Charles (2018): Making Sense Of Sounds: Data for the machine learning challenge figshare. Dataset. "https://doi.org/10.17866/rd.salford.6901475.v4"
[2]Köhn, , Stegen, F., & Baumann, T. (2016). Mining the spoken wikipedia for speech data and beyond.
[3]Siren-Identification-Localization, (2016), GitHub repository, https://github.com/Siren-Identification-Localization/Siren-Identification-Localization/tree/master/datasetsdonateacry-corpus, (2015), GitHub repository, https://github.com/gveres/donateacry-corpus
[4]Moreaux, (2017, October). Audio Cats and Dogs, Version 5. https://www.kaggle.com/mmoreaux/audio-cats-and-dogs
[5]Paszke, , Gross, S., Chintala, S., Chanan, G., Yang, E., Devito, Z., Lin, Z., Desmaison, A., Antiga, L., & Lerer, A. (2017). Automatic differentiation in PyTorch.
[6]Chandna, P., Miron, M., Janer, J., & Gómez, E. (2017). Monoaural Audio Source Separation Using Deep Convolutional Neural LVA/ICA.
[7]Kingma, P., & Ba, J. L. (2014). Adam: A method for stochastic optimization. arXiv 2014. arXiv preprint arXiv:1412.6980.
[8]Raffel, C., McFee, B., Humphrey, E. J., Salamon, J., Nieto, O., Liang, D., ... & Raffel, C. C. (2014). mir_eval: A transparent implementation of common MIR metrics. In In Proceedings of the 15th International Society for Music Information Retrieval Conference,
[9]Stöter, F. R., Uhlich, S., Liutkus, A., & Mitsufuji, Y. (2019). Open-unmix-a reference implementation for music source
[10]Stöter, F. R., Liutkus, A., & Ito, N. (2018, July). The 2018 signal separation evaluation campaign. In International Conference on Latent Variable Analysis and Signal Separation (pp. 293-305). Springer,
[11]Zeiler, M. D. (2012). ADADELTA: An adaptive learning rate method. arXiv 2012. arXiv preprint arXiv:1212.5701,